





I didn't know much about compression algorithms when I started looking into this stuff and, in truth, I still know very little. So this may all be old-hat to a lot of people but hopefully somebody finds it interesting.
What am I compressing and why do I want to compress it?
For the last month or so I've been playing around with Signed Distance Fields (SDFs) first by making some simple pictures with them and using them to handle collsiion detection and then using them as the basis of a procedural morphing animation.
I'm interested in SDFs for a few reasons: I'm not much of an artist but I do like math. If I can substitute math for art in certain situations, that potentially works to my benefit. Also, since SDFs can be used to handle collision detection and they can be updated on the fly with boolean-like operators—union, intersection and difference—they seem like they could be a good choice for modeling level geomoetry and, in particular, destructible level geometry. But mostly I just like playing with them.
In general, you create a function which returns the minimum distance from any point on screen to the surface of whatever object you're modeling and then use that distance to determine pixel colour, or detect collisions, or whatever. But calling functions, especially complex functions as SDFs tend to be, is really slow, especially if you're doing it for every single pixel on screen. To get the animations to actually animate at a reasonable speed I had to pre-calculate all the distances and store them in an array so distance checks became table look-ups. Much faster.
Creating those functions and generating those arrays required a fairly large number of tokens though. So I've been learning about compression algorithms to store those arrays directly and use a, hopefully, smaller number of tokens to decompress them.
To compress, or not to compress
Like most things, it's a trade-off: for a multi-cart system you can probably fit a decent amount of SDF data per cart; for single carts, it's almost certainly not worth it.
SDF data is big. Not as big as I had originally thought but still pretty big. Even though I was ultimately able to get quite good compression ratios we're still talking about thousands of characters worth of binary data per screen of data stored. With a fixed limit of 65535 characters, that adds up fast. In fact, as I'll discuss later, it actually adds up even faster than you'd think. Each compressed SDF only requires three tokens but saving all the tokens in the world doesn't do you any good if you don't have any characters left to use them.
Test data
I mostly used the SDFs from the animation linked above as my compression test data. Here's, sort of, what they look like as distance fields.

Left-to-right, top-to-bottom: Square, Repeated triangles, Repeated circles, Repeated squares, Star, Rotated Star, Line, and Palm tree.
It's worth noting, again, that I'm storing the actual distance data itself and not these images speciifically. The images just give a sense for how the distance fields change and how simple or complex they are. An advantage of working with distance fields in that you can use the same data in multiple ways. Here's a quick little cart which demonstates the idea:

Press 'x' to cycle through the different options. It's the same data in all cases, just being rendered differently.
How big is an SDF anyway?
At first I thought I might have to store fractional values so I'd need 32 bits per pixel. But no. In reality, at least how I'm using them so far, I'm working with integer distances on a single screen. The farthest away something can possibly be on a 128x128 display is about 180 or so along the diagonal: 8 bits is plenty.
Eight bits is definitely an improvement over 32 but still, that's one byte of data per pixel or 16384 bytes per screen of SDF data. At that size, a direct encoding of four SDFs would bust the PICO-8 character limit. The animation linked above uses eight SDFs.
So that number, 16384 bytes, is the base/uncompressed size for all my test data.
Compression algorithms
I tried a variety of algorithms both individually and in combination. These are the main ones.
Run length encoding (RLE)
RLE compresses by replacing a run of identical distances with a single instance of that distance and a number representing how many times it occurs before changing.
It was my assumption that RLE would be a bad choice for SDFs because, although some have long runs of repeated distances, most distances change with every pixel. If your run length is always one then instead of storing one integer per pixel, you're storing two.
Even so, I figured I'd test my assumptions by actually trying it and, sure enough, RLE on its own makes distance data larger, not smaller.
Huffman Coding
A Huffman coding encodes each unique distance with a different binary representation. Not all distances are represented with the same number of bits and the encoding is built in such a way that values which occur often use fewer bits than values which occur more rarely.
On its own, Huffman coding gave similar levels of compression as the LZW algorithm below.
Lempel-Ziv-Welch (LZW) compression
LZW is sort of, but not really, similar to RLE. It doesn't look for runs of identical distances but instead looks for sequences which it has seen before. When it finds one it inserts a reference to that sequence, essentially saying, "take that thing over there and put it over here as well."
Vector Distance Transform (VDT)
Once I thought to search for distance field specific compression algorithms, I found this paper describing VDT and it's the basis for the approach I decided to take so I'll describe it in a little more detail.
Rather than assigning a distance to each pixel, VDT assigns a vector to each pixel. The vector indicates which other (previously calculated) pixels, if any, can be used to calculate the distance for the current pixel. If we calculate pixels left-to-right and top-to-bottom then there are four possible vectors: the pixels directly above the current pixel, the pixels directly to the left of the current pixel, the pixels diagonally up and to the left of the current pixel, and the null vector indicating that the current distance can't be calculated based on previous pixels.
Since there are four possible vectors, each vector can be represented by two bits and the entire array of vectors takes up a total of 4096 bytes. Each null vector indicates a distance that we can't calculate and have to store directly, adding an additional 8 bits each, while every non-null vector is a distance that can be entirely eliminated from our data for a net savings of 6 bits each.
VDT on its own can reduce the size of an SDF fairly dramatically. But a nice feature of VDT is that, once the distance prediction step is taken, the vector data and remaining distance data can be further compressed using other methods. For instance, although RLE doesn't do so well with raw SDF data, it does a great job on the resulting vector data.
I tried two approaches and they gave very comparable results. Both start by doing the vector distance transformation.
The first approach then applied the RLE algorithm to the vector data and a Huffman coding to the distance data, finally combining the result into a single binary string.
The second approach starts by combining the vector and distance data into a single binary string and then running the LZW algorithm on that string to compress it further.
Below is a summary of the results I got via various methods. The VDT+LZW columns could just as well be VDT+RLE+Huffman since the results were very similar.
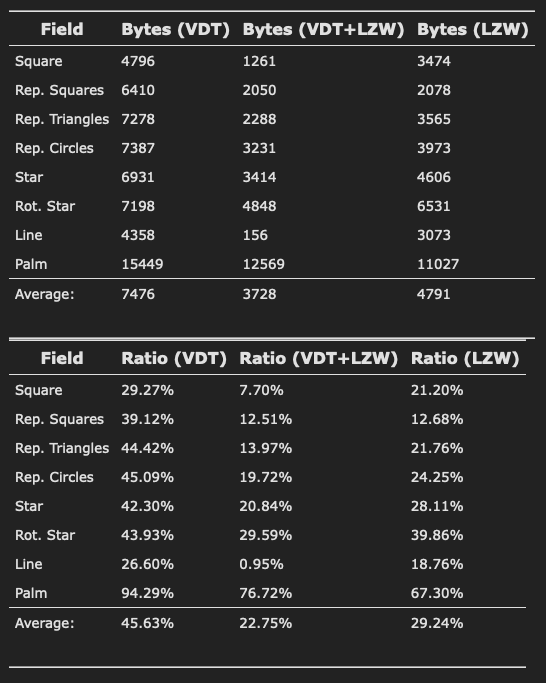
Lossless vs Lossy
I suspect that the palm tree SDF compresses so poorly because it contains a bunch of non-linear transformations: sines, cosines, exponentials, etc. which means the distance field isn't "well behaved" and, therefore, difficult to predict.
The VDT algorithm is lossless by default—it only removes a distance which can be predicted exactly—but is easily modified to be lossy. I wanted to see if I could get the palm tree SDF down to a more reasonable size without degrading the quality too badly. Spoiler alert: not really. It's easier to see when rendered as an image:

The first image is the lossless version as listed in the table above. The distortions in the second could be acceptable in some situations but still only gives a 74% compression ratio with a maximum squared error of 5. The last image, which looks like Thanos had a personal vendetta against trees, has a max squared error of 10 and still only compresses down to about 60% or a little under 10000 characters!
Compressing less to compress more
One particularly interesting discovery I made was that—even though the VDT+LZW combination gives the best compression on average—the best way to fit more SDFs per cart was to use VDT only. Why should that be the case? VDT by itself gives the worst compression of those listed. How is that better?
I figured this one out by accident when I copied the binary strings, except for the palm tree, into a cart, ran INFO and saw this:
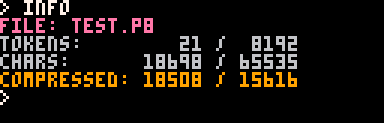
The raw character count and the compressed character count are nearly the same. Which actually makes sense: I've compressed the data significantly so whatever algorithm PICO-8 is using to compress code isn't able to squeeze much more out of it. That particular screen shot is when using VDT+LZW but the same thing happens when using LZW only, Huffman coding only, and VDT+RLE+Huffman coding.
That got me thinking: PICO-8's compression is probably better than mine. So what if I only used VDT and let PICO-8 compress it the rest of the way for me? Here are the same seven SDFs with only VDT encoding.
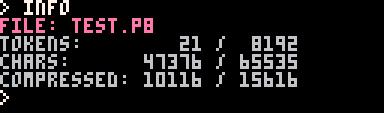
It uses up a lot more of the raw character count but the compressed character count is much lower and there's still room to spare!
Edit: I forgot to actually post the compression/decompression code anywhere so here's a cart demonstrating it. The code is also on github



Hi, @jasondelaat:
- While I must admit I understand very little of professional compression algorithms, I'm also not understanding why it's difficult to compress that palm tree effectively without introducing graphic artifacts.
I've written data compressors for Pico-8 in the past. Let me take that image and see what I can come up with.
Gold star for your very thorough introduction to advanced compression methods.
Hey, thanks!
I'm sure the image of the palm tree can be compressed quite a bit but it's not the actual image that I'm trying to compress but rather the distance data. It's just hard to visualize raw distance data without an image of some sort.
But yeah, RLE (or something else) on the image itself would probably do a pretty decent job but then it wouldn't be useful as a distance field anymore. So it goes.

I used for my current project the lzw-compression (because it doesn't need many tokens) and store the data in the rom-part (0x0000-0x42ff).
With reload() and store() you can manipulate the rom-data from different carts, for example a game-cart, a compress-cart and an editor-cart. With this I can change the packed-data without changing the source-code.
With this methode you have additional 17152 Bytes of compressed data - which doesn't count to the source code or compressed-limit.
I recommand to activated the high ram from 0x8000-0xfff for more space to (un)compress and handling of the data.
btw. one problem of compressing data in an binary string is, that the data will compressed twice (your code and pico8-compression) - that is normally not a good idea, because it can result in a bigger file.

I've come to similar conclusions myself when it comes to compressing spritesheet and map data. I've spent time testing various compression setups, but for building compressed strings it seems the most efficient approach is something simple like RLE that doesn't obscure bytes and plays nice with Pico-8's pretty powerful built-in compression.
If you want to store compressed data directly in memory, though, that's another story.
@JadeLombax
Yeah, I was wondering about that. I mean, it makes sense that it would be an issue regardless of what you were compressing but this was my first real foray into compression so I wasn't sure my instincts were entirely trustworthy.
Nice to know I didn't imagine it and it's not just a result of me having done something wrong though!

I was curious to know just how much of that palm-tree picture could be compressed using my own method and code.


1726-chars. A fair amount it seems !
@jasondelaat, can you use this distance method you are describing to create a better compressor ? I think picture compressing and decompressing is always of interest to the Pico-8 community for use in logos, instructions, game credits, and losing and winning screens.
I tried out the palm tree image with my latest sprite and map data decompressor function, which is just an efficient RLE implementation. Combined with Pico-8's built-in compression it squeezes things down pretty well, just 1568 chars and 821 bytes, just about a 10:1 compression ratio.

Don't know if my version of RLE would be very useful for SDF's, as it encodes pixel color and span length into a single character, but I was curious.
1568, @JadeLombax ? Nice ! And your code is so small too.
Let me copy your code to the clipboard and paste.
. . . ?
Oh no it's not showing properly !

Wait ... I forgot to press CTRL+P puny mode. Paste. There's the palm tree.
Hmm ... I didn't have to do that with my code. Are you coding 8-bit or 7-bit ?
I use a range of 240 possible characters, so the smallcaps chars are in there.
240 ? Wow, so yeah, CTRL+P was needed. Is it possible to get 256, @JadeLombax ?
And yes, my data is 7-bit.
@dw817, @JadeLombax
Holy smokes those are some impressively compact decompression functions!
I'm not terribly surprised that the image itself can be compressed significantly, I pretty much assumed that would be the case given that it's only four colours in fairly large solid blocks.
At the moment I'm not too concerned about compressing a particular image but rather the underlying distance field data. Which, in fairness, I probably didn't explain too well in this post.

This is two images but it's only a single set of data with the only difference being the "post processing," if you will, of how colours are being assigned to each pixel. The images themselves are fairly compressible—well at least one of them is—but it's the underlying data that I'm talking about in this post.
I don't know if you've watched the animation I linked at the top of the post but if not I'll embed it below: Give it a look. I could be wrong, I'm still fairly new to graphics stuff generally, but I don't think I could do that with just image data except by having dozens of individual animation frames.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
It's possible to use the full 256 chars via the use of escape sequence code (though I'm not sure if blocks of data like that are compressed the usual way), but if you want to avoid that, I believe the maximum range is 251, which requires use of a small lookup table.
@dw817
I'm not entirely sure but I think the PX9 data compression uses a similar algorithm to the one I'm using. I'm just judging by the description and haven't actually looked at the code but I'm sure @zep could enlighten us if he were so inclined.
And yes, you can use 256 values! My algorithms use the full possible character set but you do have to take the extra step of escaping special characters which inflates the character count a bit.

@dw817 JadeLombax probably went with 240 to avoid the first 16 control code characters, as they can mess with things. Most seem pretty harmless and aren't going to get in the way unless you print them, but character 0 (iirc, might be 1) is a huge annoyance. It seems to mean "end this string", regardless of if you're printing it or not. Potentially might be how p8 marks the end of a string internally? Regardless, it's annoying and gets really in the way with this kinda stuff. I've taken to writing that kind of data into ROM instead whenever I can.
You could probably pull off 255 characters if you really wanted to, but I don't know what the other half of those control characters even do. It's probably best to steer clear of them whenever possible. Especially considering there might be some blank ones in there that might get functionality later.
edit: whoops, i was a little too slow, heh
Pardon my ignorance, but are you basically saying that you're storing 8-bit depth values for each pixel, then calculating the distance from a fixed position to each point in 3d space?
@jasondelaat: Nope, I didn't see the animation. Seeing it now. Oh yeah that's way beyond my scope. Looks beautiful tho.
Here's an idea I was thinking of this morning. Looking at that palm tree picture, what if it were broken down to the most intelligent rectangles ? That is ignore the curves for now but write code to intelligently determine the best rectangles. Lemme draw that to give an idea.

And this is not perfect. No you'd have a program that would scan the whole picture and determine the very best, biggest, and least number of solid-colored rectangles to recreate the whole picture perfectly.
For instance the 5-rectangles above only take 4- 7-bit characters for each pair of X/Y coordinates to make the rectangle and one more character for the fill color. Yielding 25-string characters or even less binary bytes if stored in sprite or mapper area.
And you could cut that down by many more characters in size if you had a program determine it were possible to overlap colored rectangles realizing what the end picture would be so you would use less count of same-color rectangles.
For instance, it could look at the picture and determine the background is red by the size - it covers the screen. So then it would fill the entire screen with red. Then make another rectangle a bit smaller than the whole screen for the orange, then yellow. Then fill in the details from there.
And this is not impossible. When I worked in Flash years ago you had a function that could turn JPG or GIF pictures into vectors taking a tremendously great deal smaller space yet retain most of the image itself.
@JadeLombax
8-bit values for each pixel, yes but in this case 2D not 3D. You can do 3D but I'm not. And they're not used to calculate the distance, they are the distance from that pixel to some defined surface. There could be multiple objects in the SDF so, more generally, the value is the minimum distance to a surface.
They're signed distances so a positive distance means the point/pixel is outside of the object while a negative distance means the point/pixel is inside the object. The surface of the object is defined as all points where the distance equals zero.
The VDT algorithm works by figuring out which distances can be calculated using other distances and eliminating as many as possible. But yes, the uncompressed data is an 8-bit value per pixel representing a distance.
For instance, in the section on test data the images aren't what I'm compressing, they're just showing the "field" or how the distance changes. The first one with "concentric" squares is actually just a single square from (32, 32) to (96, 96). That's the surface where the distance equals zero. Outside of that distances increase in the positive direction and inside they increase in the negative direction. And similarly for the other images in the set.
SDFs are frequently used for 3D stuff. They're the basis of a lot (most? all?) of the cool stuff you might see on shadertoy. (I don't do things on shadertoy, I'm merely aware of its existence.)
Edit: I first learned about SDFs from this video. Then found a wealth of information here. The palm tree we've been discussing is an adaptation from this tutorial.
JadeLombax:
> It's possible to use the full 256 chars via the use of escape sequence code (though I'm not sure if blocks of data like that are compressed the usual way),
Yes binary data can compress well: https://www.lexaloffle.com/bbs/?tid=38692
Hi @merwok:
I'm seeing this. It's exciting stuff yet ... for instance to have character \ you must use \ or for character chr(0) it is \0. This means you are taking 2-source-code characters for character zero.
While you might be able to access the entire 256-characters for compression as a string, your compression string even if based on 8-bit is likely going to be bigger than our current compressions of 1726 and 1568.
Especially if the screen had a lot of black in it. Unless something changes I think I'm going to stick with 7-bits for compression. In this every single byte I save in my code truly only takes one byte of source-code.
While @JadeLombax is using a whopping 240-characters for superior compression. I'm not content it's dipping into other characters like " and \ especially since they must minimal take 2-sourcecode characters. There is the possibility of compressing a picture that might convert mostly to " and \ and then it can happen - the compression is bigger than the decompression.
Now if @zep will create something like THIS idea I'm gonna say, I think everyone will benefit. I had this idea 15+ years ago when deciding I did not want data files to be external from source-code for my game making language.
ilogo=(special box character)230400 the next line had 2-characters per byte hex, so in total there would be 460800 characters visible on that line. In this you could store whole OGG songs, 320x240x3 pictures, really anything here. next line after this returns to normal code iclick=(special box character)8734 this line had 2-characters per byte hex |
So to do this in Pico-8 you could have:
function _init()
ilogo={*8192}
2-character hex
end
|
This means the string ilogo is expecting to see 8192-bytes of data on the next line. Zep could create 8x8 sprites that look like this.
|
|
[8x8] |
Or just use the standard character set, in this case 512-characters would be displayed yet it will still be stored only as 4-bytes and not 8 or more as it might appear:
000F3FFF |
Now this is a little tricky. If it can be done without going magic - do so. However since Pico-8 is a Fantasy console it you can kinna breaking the laws of physics here. While the data is read and interpreted as a single byte, in truth if you read the raw .P8 it is 2-hex characters read internally in the system. You are not penalized though and actual storage space in your source is truly 1-byte, and may even appear as the special characters I drew above.
By telling the length of the data above with {256} or any number like {8192} etc. You could store any 8-bit data no problem at all and each character would represent one byte. But it must be on the next line and no commands at all can be used on that line additionally. It is solely for 8-bit data. Zero is not needed to denote the end of the data either as the line previous states exactly how many bytes you are going to record there.
By "virtual" storage this gets past the "impossible" dilemma of storing CHR(0) and its remaining 255 other states. And any data could be used at this point. To the programmer it truly is just one-byte and in all cases only penalizes the programmer for a single byte. To Pico-8 it truly is 2-bytes to manage and work with to ensure the source-code can be interpreted and read later.
This would also force all source-code at a NOTEPAD level to use just the standard characters and never the ones exceeding 126 or less than 32.
Now if someone has a different way of getting past the "zero dilemma" while still using a single byte of storage - I don't know how to do that and would like to see.
Yeah, I'm only using a single character for each value, but since symbols 34 ("), and 92 (\) are problematic, I have to use alternate symbols in the strings instead (14 and 15), which are then corrected by the decoder. The only symbols that can't be used without escape sequences are those for 0,10,13,34, and 92.
If you like, I could post the code for an encoder/decoder that uses 251 possible symbols.
Please and definitely ... We can all learn code from each other.
I'm going to work on a new one myself. I just had an idea how to compress and store the screen using 8-bit including zeros and stuff.
Am I right though ? That if the picture does contain whatever escape sequence that cannot be converted to a single byte, that the compression would exceed the size of the decompressed video ?
I think it would be awesome if @zep suddenly announces the new version of Pico-8 can include any # of external p8 files with your primary when you post online. So when you post a cart you can include all the "restore" files you want as accessible data to your primary cart.
Alright, I'll work on getting a little cart put together. Not sure how much escape characters would increase file size. True, they add to the character count, but it's the compressed byte size that's most important. I'll probably have to do some testing on that front.
@JadeLombax, @dw817
I suspect it doesn't affect compressed character size too much, depending on your data. Since there are only 5 characters—about 2%—which require escapes you're only looking at an extra 20 characters for every thousand characters of compressed data on average. That assumes that every 8-bit sequences is equally likely in your data which may or may not be a valid assumption.
I managed to get quite a bit higher compression than 1568. Yet I also feel like we ( @JadeLombax and me) hijacked this thread - and I apologize for that.
Once I've perfect it I'll start a new thread so @jasondelaat can continue his teaching on SDFs and Jade and me can continue to tussle with best picture compression, methods, and coding ...
Also to hopefully attract other people wanting to take a hand at image compression and decompression with minimal coding space. Always open to learning new methods.
Yeah, sorry for taking things off on a tangent, I think starting another thread is a good idea.
That said, I have an idea and I'm wondering if it might be of some use for the original sdf application. You posted several pictures that use colors to represent height changes for different points, and I was wondering if it's feasible to store the data this way, using 16-color pixels to store height change values instead of using bytes to store absolute height data. I mean, if the changes are within the correct range (which they may not be), the magnitudes don't necessarily have to match, you'd just need to specify an initial offset.
@dw817,
No worries. The thread's about compression, you're talking about compression. Seems fine to me. I'm finding it interesting anyway. Though, that said, if you're looking to draw more people into the conversation this might not be where they're going to look for it.
@JadeLombax,
That's a great idea. I know some people use SDF textures which are generally gray scale images with the amount of gray representing the distance from the surface (as in this paper from Valve .) I dismissed the idea initially because...well no gray scale in PICO-8 and only 16 colours. But actually I think you're right. I just need some convenient starting position and can change the distance by some fixed amount every time the colour changes. Sort of like a flood fill for distances. I'll have to give that a try. Thanks!
Also, all this discussion and I realized I didn't actually post my compression code anywhere! I've edited the original post and added a cart with the compression/decompression code in case anyone cares to take a look at it. I haven't made any attempt to optimize tokens on it so far so I'm sure it could be considerably smaller. I was mainly concerned with making it work.
Okay, if that's useful that will be pretty cool. I guess it would only give you around 8 potential delta values in each direction, but if the heights don't change drastically from pixel to pixel it could work.
I was curious how much an image like that would compress, so I ran the height change picture of the palm tree through my RLE compressor in both base 240 and base 256, and both times I got a compressed size of 7314 bytes. But then I tried just raw hex and got 7122, so in this kind of situation maybe the best move is just to entirely rely on Pico-8's built-in compression.
@JadeLombax and @jasondelaat, I have finally finished my 8-bit compressor. Thanks especially to Jade for showing me its possible to have 8-bit decompression in code.
You can find it HERE:
https://www.lexaloffle.com/bbs/?tid=45335
And YES ! I would definitely like our thread to continue there regarding the quest in best picture compression techniques and coding.
[Please log in to post a comment]