






{kind=link}
So I was writing some compression functions and I think I found a bug with the token parsing in PICO-8.
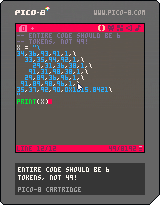
Here's the code:
-- entire code should be 6
-- tokens, not 49!
x = "\
34,36,93,91,1,\
33,35,94,92,1,\
29,31,36,38,1,\
91,31,98,38,1,\
29,89,36,96,1,\
91,89,98,96,1,\
35,37,92,90,0x1015.8421\
"
print(x)
|
Pico-8 claims the code size is 49 tokens, but there is just a big string here that looks like it has sub tokens. Overall size should be 6 tokens :).
1


Try it this way:
-- entire code should be 6
-- tokens, not 49!
--
x = [[\
34,36,93,91,1,\
33,35,94,92,1,\
29,31,36,38,1,\
91,31,98,38,1,\
29,89,36,96,1,\
91,89,98,96,1,\
35,37,92,90,0x1015.8421\
]]
print(x)
|
Wow, I didn't know about that! I'll def use it now. But I still think the string parsing thing should be fixed, since the code compiles, the token count logic is just off.

[Please log in to post a comment]