





There are many ways to loop over an array-style table. For example:
local tab = {10,20,30,40}
-- method 1
local calc1 = 0
for i,elem in ipairs(tab) do
calc1 += i*elem
end
-- method 2
local calc2 = 0
for i=1,#tab do
local elem = tab[i]
calc2 += i*elem
end |
Which way is fastest? Well it often doesn't matter, since the work inside the loop usually far outweighs the cost of the loop itself. Or tokens might matter more to you than speed. But in some situations you want your code to be as fast as possible, and that means minimizing the overhead from the loop itself.
Setup
So, which way of looping is fastest? Here are the methods we'll compare:
function for_i(tab) for i=1,#tab do local x=tab[i] -- do some work end end function for_all(tab) for x in all(tab) do -- do some work end end function for_ipairs(tab) for i,x in ipairs(tab) do -- do some work end end function for_inext(tab) for i,x in inext,tab do -- do some work end end function for_each(tab) foreach(tab, function(x) -- do some work end) end function while_i(tab) local i = 1 while i<=#tab do local x = tab[i] -- do some work i += 1 end end function while_isize(tab) local i,size = 1,#tab while i<=size do local x = tab[i] -- do some work i += 1 end end -- note: issues if tab is empty function repeat_i(tab) local i = 1 repeat local x = tab[i] -- do some work i += 1 until i>#tab end -- note: issues if tab is empty function repeat_isize(tab) local i,size = 1,#tab repeat local x = tab[i] -- do some work i += 1 until i>size end |
edit: In my analysis below I'll refer to some extra methods (mainly based on reader comments). I haven't updated the graph/chart for these methods:
I used my cycle counter to measure how long each function takes to run on arrays of various lengths -- every length from 0 to 80. The results are uninteresting after length 25, so I've truncated the table and chart below.
Here's my measurement code. It prints out a csv of cycle data to the host console. It's not too interesting to run the cart, but here it is if you want to reproduce or check my results:


{kind=link}
Results
I ran my measurement cart (#loop_overhead, above) on PICO-8 0.2.6b for Linux. Here's the data; higher numbers are slower/worse.
len,while_i,for_each,while_isize,repeat_i,repeat_isize,for_i,for_ipairs,for_inext,for_all 0,5,30,5,8,8,8,18,9,21 1,14,51,12,8,8,12,20,11,36 2,23,57,19,15,13,16,22,13,36 3,32,63,26,22,18,20,24,15,36 4,41,69,33,29,23,24,26,17,36 5,50,75,40,36,28,28,28,19,36 6,59,81,47,43,33,32,30,21,36 7,68,87,54,50,38,36,32,23,36 8,77,93,61,57,43,40,34,25,36 9,86,99,68,64,48,44,36,27,36 10,95,105,75,71,53,48,38,29,36 11,104,111,82,78,58,52,40,31,36 12,113,117,89,85,63,56,42,33,36 13,122,123,96,92,68,60,44,35,36 14,131,129,103,99,73,64,46,37,36 15,140,135,110,106,78,68,48,39,36 16,149,141,117,113,83,72,50,41,36 17,158,149,124,120,88,76,52,43,38 18,167,157,131,127,93,80,54,45,40 19,176,165,138,134,98,84,56,47,42 20,185,173,145,141,103,88,58,49,44 21,194,181,152,148,108,92,60,51,46 22,203,189,159,155,113,96,62,53,48 23,212,197,166,162,118,100,64,55,50 24,221,205,173,169,123,104,66,57,52 25,230,213,180,176,128,108,68,59,54 |
And here's a chart:
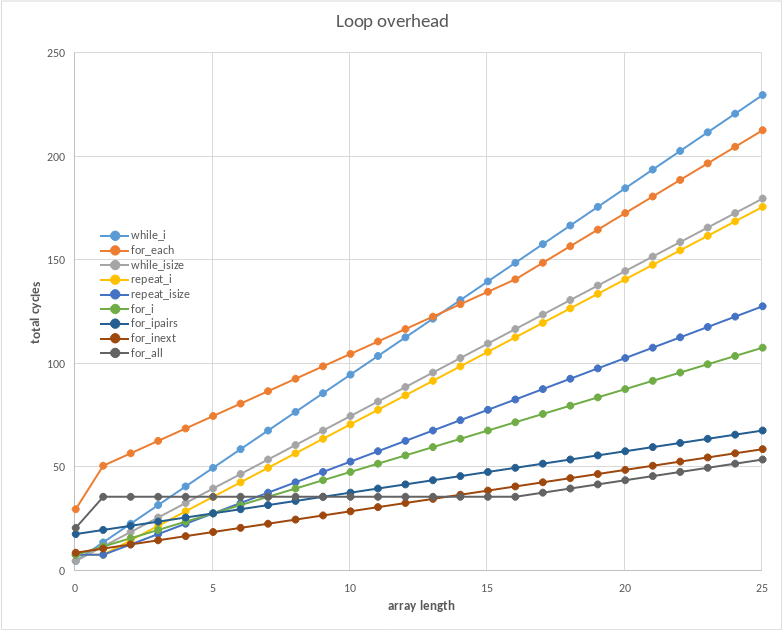
(For colorblind folks, the labels are stacked in order of their performance at length=25)
Commentary
for_inext()
The clear winner here is for_inext() -- it's the fastest in most situations, you get access to both i and x inside the body of the loop, and its token count is nearly the best as well (just 1 token more than for_each()).
Downsides: it's an unusual bit of code that might trip up other people reading it. inext() is defined by PICO-8, not Lua, if that matters to you. Compare against Lua's next(). But these downsides seem unimportant if all you want is to make one particular PICO-8 cart run as fast as it can.
for_all()
However, when looping over medium/large arrays (length>=14), for_all() is a bit faster than for_inext() -- exactly 5 cycles faster when length>=16. But for_all() is much slower than for_inext() up until that breakpoint. When length=2, for_all() takes 36 cycles versus for_inext()'s 13 cycles -- nearly 3 times as slow!
Other possible downsides: index i is not accessible inside the loop.
all() has some special tricks that let you delete while iterating (within limits), which may be considered an upside or a downside. See the conversation starting here for details.
for_all() has the strangest timing out of all the options tested. At low array lengths it performs second-worst, but at medium/high array lengths it performs best.
for_i()
Despite feeling like one of the more natural ways to write a loop, for_i() is noticeably slower than for_ipairs()/for_inext()/for_all(). Specifically, for_i() costs 4 extra cycles for each extra iteration, compared to 2 cycles for the best methods. For large arrays, the choice between for_ipairs()/for_inext()/for_all() mostly doesn't matter, but for_i() will be noticeably worse.
for_each()
for_each() has the lowest token-count but is one of the slowest options here. It only beats for_inext() by a single token, so I would generally prefer for_inext().
slope change in for_each() / for_all()
At length 16, the slope of the for_each() and for_all() lines change slightly. This isn't a mistake in the measurement; all() artificially adjusts its cost starting at length 16, and foreach() is a thin wrapper around all() and so it inherits this cost weirdness.
while_isize() versus while_i()
while_isize() is faster than while_i(), but for_isize() is 1 cycle slower than for_i(). This is because while-loops re-evaluate their condition every iteration, but numeric for-loops only evaluate their bounds once.
while_i() versus repeat_i()
I was surprised to see that repeat_i() is quite a bit faster than while_i(). Why are they so different? It helps to look at the generated Lua bytecode using a tool like https://www.luac.nl/ -- you can see that while_i() uses an extra JMP instruction that can be avoided with repeat_i().
As you might expect, goto-based loops perform exactly the same as while_i()/repeat_isize()/etc, since they compile to the same bytecode or similar.
for_next() / for_pairs()
for_next() and for_pairs() perform exactly the same as for_inext() and for_ipairs(), respectively. It would be a bit odd to loop over an array-style table using next()/pairs() instead of inext()/ipairs() with their guaranteed iteration order, but it's good to know there's no performance difference. (and nice to know that looping over key-value tables is quite fast)
Conclusion
I see four viable options for looping:
- for_inext() is generally the fastest method:
for i,x in inext,tab do -- do some work end
With arrays of length 2 to 13, it's the fastest option, but it performs excellently at any array length. At higher lengths, it's 5 cycles slower than for_all() -- 5 cycles for the entire loop, not 5 cycles per iteration. Most other methods have additional cost per-iteration, as shown by their higher slopes in the chart. At high array-lengths the differences between for_inext(), for_ipairs(), and for_all() become less and less significant -- they each only cost 2 extra cycles for each extra iteration.
As a nice bonus, for_inext() is only 1 token worse than the most token-efficient method, for_each(). - With arrays of length 14+, for_all() is slightly faster than for_inext():
for x in all(tab) do -- do some work end
However, be aware that all() is much slower on arrays of length 0 to 13.
- For carts with extreme token-limitations and no problem with much larger loop overhead (3-4x),
foreach()is slightly better than the alternatives.
And finally, option 4: If you don't have any particular hard limits you're up against, loop however you like! Whatever lets you type code fastest and not get distracted with unimportant timing details. You're trying to make a game here, not a pretty piece of code. This is most likely the scenario you are in!
Even if you know you want fast code, the first step is to measure your code and find out which parts are slow, and the answer probably won't be the loop overhead. Loop overhead is easy to measure, but that doesn't make it important. Don't link people to this post saying "pancelor says you have to loop THIS way instead of THAT way", it usually just doesn't matter. But if it ever does matter, or if you're curious (like I was) about how much it matters, then hey, this is the post for you. Hope it was interesting!


Thanks for looking into this! Very interesting results.
My takeaway for general use is to just stick with all(). I'm much more concerned with the iteration speed of loops with many iterations than with few.

Excellent analysis! I'm curious about loops that make use of goto, but not sure if it has caveats or memory issues that make it unusable in place of a normal loop.
Thanks! yup, sticking with all() seems very reasonable. I've edited the conclusion a bit to emphasize that at high array lengths, all()/ipairs()/inext are basically equivalent
@kozm0naut good question! I've added in a bit about goto -- search "extra methods" and "goto" for my edits. No caveats that I can think of.
I know it's probably going to be slower, but I wonder how much slower tail recursion is:
function tail_inext(tab)
local function loop(i, v)
if i then
-- do work
return loop(inext(tab, i))
end
end
return loop(inext(tab))
end
function tail_i(tab)
local n = #tab
local function loop(i)
if i <= n then
local x = tab[i]
-- do work
return loop(i+1)
end
end
return loop(1)
end |
I had tried some recursive methods but wasn't happy with them -- I was idly hoping you'd chime in with more idiomatic ones :) Thanks for these!!
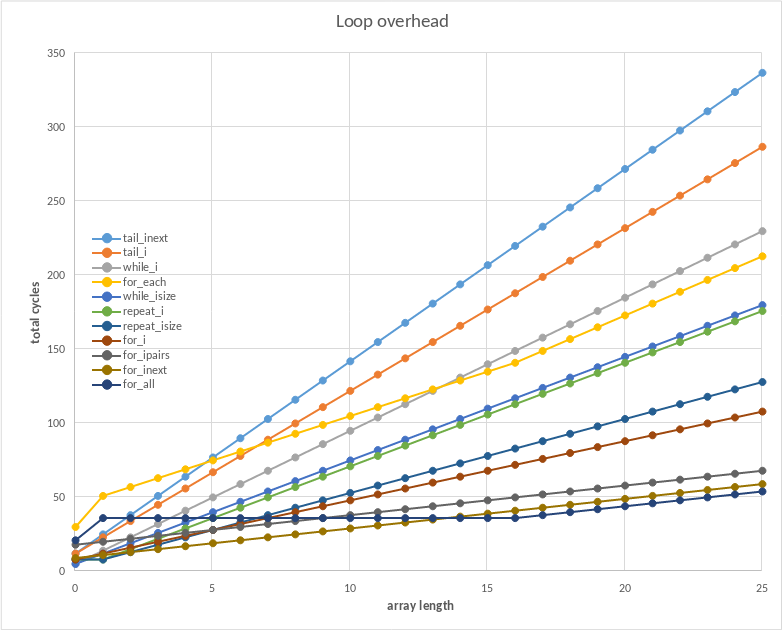
I may update the main post later, but for now here are the results:
len,tail_inext,tail_i 0,12,12 1,25,23 2,38,34 3,51,45 ... |
It continues as expected afterward -- 13 cycles per iteration and 11 cycles per iteration. So, these two are the slowest methods yet, but not too horribly slow. A 60fps game would lose 1% cpu by looping over 150ish array items. (A frame has around 140,000 cycles, the fastest loops here take 2 cycles per iteration, and 1400/(11-2) is 155)
{kind=link}
[Please log in to post a comment]