





dw817's BOOK READER AND WRITER
First off, converting a book to a cart (not just for Pico-8) is not a unique idea.
I originally saw this being used back for Gameboy Color many years ago by Jeff Frohwein. At the time he was using a font very similar to ZEP's at a 3x5 pixel scale, but also included a distorted 3x4 letters for lowercase. Surprisingly it had 32k of storage for the story, so back then it was even more capable of storage than Pico-8 is of today.
There have been countless Bible programs for the pc which claim not only to contain the entire Bible but also have a search routine so you can look for certain passages and entries.
Today I use a bookreader on both my cellphone and portable PSP handheld game unit especially for the works of Arthur C. Clarke.
So ... this idea is not new and has in fact been tackled by many people long before the Pico-8 even existed. I have many interests myself, databases and compression just being a few. I was eventually going to get around to writing a book writer and reader, and here it is.
Having looked at dddaaannn's excellent version of a Pico-8 bookreader found HERE:
https://www.lexaloffle.com/bbs/?tid=2776
I realized I would be wanting to write one that would be simpler and not as complex or require much work for others to make use of my libs. And it may not compress as well, only(62-68%) but it would certainly contain everything in the single code needed so anyone could not only read the story enclosed but additionally add their own on top of it and compile for their own use.
And in less than 260-lines of source-code. That and not require any external batch files, Python files, manual compression, or what have you.
Nope ! It's ready to run right out of the box, batteries included. :)
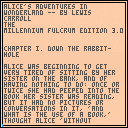
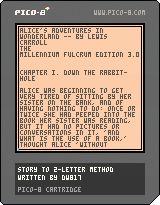
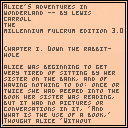
First off when you run it you get a chance to read a bit of Alice In Wonderland. Use the UP and DOWN arrow keys to navigate by sentences and the LEFT and RIGHT to navigate by pages.
Notice you have a blue and red marker. The blue marker shows where your current bookmark is and the red marker shows where you are reading in the story.
Press (X) to set the bookmark and (O) to jump to it. Bookmarks are recorded so even if you run the program again later, it will remember that same bookmark you gave it.
In the code itself, it's very simple.
Set MODE to 0 (zero) if you just want to clear out the book RAM space so you can examine for yourself it truly is cleared.
Set MODE to 1 (one) and it will take whatever is in string variable STORY and both compress and stuff it all up in memory using up to 12288 bytes maximum for it.
Set MODE to 2 (default) and you can use the book reader included in the same program to examine your book.
Memory contents 0-1 is length of book.
Memory contents 2-3 is the current position of the bookmark.
And both of these elements are handled automatically in the code so you don't need to worry about them.
Also because this cart is self-modifying, once you compress a book of your choosing via the STORY variable, you can save off the .P8 or compile to EXE or whatever and it will automatically contain the story you put in there.
It should also be possible to write the code to handle more than one story here, you know, like Aesop's Fables, so you have a list of stories to choose from. Depending on the interest shown in this, I'll consider it.

{kind=link}
{kind=link}
Here is an interesting variation. the "strange" compression I mentioned I was working on and just now finished.
It's only good for books and yet with no bit compression or bit conversion, you can still get a cool 66% compression file. Not bad.
_000.png)
So how do you think I did it ? Remember, no bit conversion took place yet data is still compressed.
Give up ? :)
The method I chose here I suspect is an original one and it uses a single byte to represent more than one character definition. The first characters are normal, however, 0-63. They are single ASCII characters including letters, digits, and ! @ # and the like.
Then it gets tricky. You have all the letters A-Z with the 2nd character being a vowel AEIOU. This takes 130 characters. Then all the letters A-Z doubled, another 26. Then all the letters A-Z followed by a single space. Another 26.
So how many characters left remain for that single byte after all these normal and custom definitions ?
64(c)+26(a)+26(e)+26(i)+26(o)+26(u)+26(d)+26(s).
a..z 0..9 ba..za be..ze bi..zi bo..zo bu..zu aa..zz a[]..z[] |
or read that as 64-chars + 26 of (a/e/i/o/u) + 26 doubled + 26 followed by space. Ensuring there are no duplicates that leaves only 15-chars remaining !
And these 15-chars are not forgotten, no, I take them into account as well with the custom character set of:
"blbrchclcrdrflfrglgrplprshstsl" |
Where 2-of each of these characters that count as 1-byte each are searched for and compressed from the matching 2-character search.
And there you have it ! 256-chars to comprise a single byte. Then store it, then retrieve it back with the book reader.
Can you think of another way to compress text without using bit-conversion ?

Have you thought of short words that are often used + the space? i.e. the/of/and/a/you/it/them, etc. for instance,
"a ", "the " etc. I'm curious how you dealt with spaces in general actually or is that just part of the 'other characters' like @,#,$ etc?
Hi Hseiken, thanks for writing !
There are 2-kinds of spaces. First off, I'm searching my table backwards so the default 64-chars are checked last.
In that 64-char. table there is a single space to itself. Before that is checked though there are 26-char definitions that look like this:
"a ","b ","c ","d ", ...
I check the text to see if there's a match with those first before I check for a space all to itself.
And no, I didn't do actual words. Hmm ... That is certainly a possibility. Perhaps ... I could find out what the most common words are in English vocabulary and build a 192-table around that.
Not today till evening tho as I see my niece and family most of the day.
Interesting idea to use true standard words. Thanks for the suggest !
You can try to scan the text itself to see what the most common chains of letters are within it, as well, up to 3 or 4 letters long.
They finally headed out. So I'm messing with this again.
It's a good idea you have hseiken, but I want to be able to use a generic dictionary for anyone so they can put their own story in variable story, compress, and see it in a viewer. Not just Alice In Wonderland.
I've completed the first 2-parts. I have the dictionary, 192-most commonly used words in the English vocabulary sorted by frequency, filling the lookup 64-255. 0-63 is just a normal A-Z, 0-9, extra chars lookup.
And the code to read the story and compress it.
So far it seems I'm only going to get 68% compress. It's 99% compress size with no dictionary at all so - the dictionary is helping to cut down the size of final compress - but apparently not as much as my double-char idea or straight 5-bit to 8-bit convert.
Here is the code. I'm thinking maybe I don't need all those special characters in the 64-set. Will try and cut it down to give me a bigger dictionary.
Complete. Let's see the results.
If you look at the data (sprites), you can see this is definitely not a good compression as there are patterns of lines in every even pixel across.
I didn't get this with the 5-bit or 2-char method.
I wanna see for myself if it bumps up the compression at all. Can only hope.
Okay, here is the code for that with a 214-word dictionary. Standard special chars (only special chars) are 0-9, a-z, and . ! ? , - and space, nothing else, for a size of 42 chars.

{kind=link}
Had to cut down the book size to compensate to make it fit in the 12288 area. Ah, not much better. Looks like my 5 to 8-bit conversion is the best so far. Fastest to compress too.
Here is the current scoreboard:
214-word dictionary, very slow compression 68.1259% 2-char method of mine, medium speed compression 65.4282% 5 to 8-bit, fast compression 63.2324% |
So I'm looking to beat and get lower than 63.23% if at all possible. And the method you choose can be used for other stories without having to alter it's compression because of changed story content.
Seeing as lowercase is desirable, here it is with uppercase and lowercase letters, and no change to compression (which is the 5 to 8-bit I decided)
Here it is:
{kind=link}

Do these compressed carts allow me to use any of the sprite/music editors?
My goal is to make a short text adventure game with simple character sprites using this.
[Please log in to post a comment]