






Here's a 7500 word dictionary cart for making word games and whatnot. It contains the most common 3-6 letter words according to wiktionary.com, including proper names. The loader is 264 tokens, and the data is 11317, stored over the full map (including shared gfx), plus the last 44 SFX. So there are just 128 sprites and 20 SFX spare. The 5 most common and 10 least common words on the list are:
THE AND THAT WAS HIS RADIUM BAWL LINTEL WAFER WELTER AUNTY OPTICS SIKH LIL BARB |
Technical details..
The data is generated using a convoluted toolchain process, that I'll post later on if I find time to organize it into something useful.
The compression works by enumerating every possible word in order of word size first, and then alphabetical order. So, A is 0, B is 1, AA is 26, and so on. This means that to store the whole dictionary, only the distances between each word's index is needed. There are many clusters of close words (e.g the distance between CAN and CAP is only 2), so the distances are sorted into range categories depending on how many bits are needed to store each range. Repeated categories are common and so can be encoded with a single bit -- otherwise a 3-bit value is used to store the category for each distance. The encoding utility greedy-searches sets of 5 category bit-lengths and a roman cypher to try to optimize the encoded size, which saved around 1k compared with hand-optimizing the parameter set.


@zep:
I analyzed the resulting dictionary to see if you could prune your 'potential' dictionary at all to reduce distances. I was looking for letters that didn't start a word, end a word, or follow a certain other letter, e.g. "qz". There's one invalid starting char, two invalid ending chars, and 249 invalid pairs, encoded into a string of 1+1+26=28 lists here:
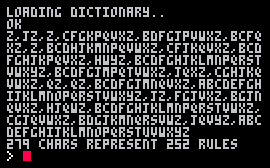
Also note that you only need 5 bits per char, so those 279 chars plus terminator could probably fit in about 175 bytes.
I wrote some code to work out the reduction in potential dictionary size, based on those rules. I'm getting a figure of about 17.7% of the original size for a 1-to-6-letter-word dictionary and 12.8% for a 1-to-7-letter-word dictionary, assuming I'm calculating correctly.
Now, I'm not sure that pre-eliminating entries from the dictionary will get you longer/better runs of valid/invalid words, but it's possible. Distances should be shorter in general. The cost to include the rules is pretty low, so it wouldn't take much to make it worth it.
Mind you, with more room comes the urge to add more words. Obviously the number of rules will probably decrease as one adds words. Add "zoo" and the "doesn't start with 'z'" rule goes away. Add "pizzazz" and "raj" and we lose both of the "doesn't end with" rules too. Still, a lot should remain.
Anyway, I had food for thought and decided to split the meal with you. :)
PS: Here's the text from the image, if you want to play around with it quickly. It's just <invalid starts>,<invalid ends>,<doesn't follow 'a'>, ... ,<doesn't follow 'z'>.
z,jz,z,cfgkpqvxz,bdfgjpvwxz,bcfq xz,z,bcdhjkmnpqvwxz,cfjkqvxz,bcd fghjkpqvxz,hwyz,bcdfghjklmnpqrst vwxyz,bcdfgjmpqtvwxz,jqxz,cghjkq vwxz,qz,qz,bcdfgjmnqvxz,abcdefgh ijklmnopqrstvwxyz,jz,fgjvxz,bgjn qvxz,hjqwz,bcdfghjklmnpqrstvwxz, cgjqvwxz,bdgjkmnqrsvwz,jqvyz,abc defghijklmnopqrstuvwxyz |


{kind=link}
{kind=link}
a two-years-old cart that belongs in this thread, I think ;)
the dictionary is stored in a tree, which takes a huge amount of memory (twice as much as storing the full words as table keys like zep did IIRC). it seemed easier to roam at the time, but now I think you could get away with scanning a list back and forth (maybe decompress from original data, on the fly?).
I started this with a bookworm or boggle in mind, but soon realized that this particular dictionary didn't fit that kind of game (lacking too many common nouns while including many proper nouns). so eventually I went for a hangout game instead (Demonspell)
also I had started compiling another dictionary, only singular common nouns. I hadn't tried stuffing it in a cart, but since there's now a multicart system maybe a dedicated dictionary cart could be handy? I'll post about it when (if) I can put my hands back on it ;)

I like this, UB. But how about a game ?
May I suggest the object of the game is to guess and type all the words in the dictionary through a rudimentary type of hangman game.
A list is kept too so the player can see what words they've already done. Points are given according to how many characters there are in each word.
And of course the ability to SAVE your progress. You can easily save 8-bits of information per byte using the standard cartdata() functions so that would yield 2048 flags.
Perhaps then just choose 2048 words the player needs to guess and type ? If they get hung and don't get the word, no flags are changed and a new random word is chosen.
But if they =DO= get it correct, that particular flag # is set and a new random word is chosen with the understanding the one they just guessed will NEVER be chosen again - unless the player's data is reset.
So the object of the game is ultimately for the player to guess all 2048 words, at which point they get particle explosions and fanfare. :)
If you need some data space like 2-bytes to keep track of score, you could take 48-bits away yielding 6-bytes for personal player data use and still have up to 2000 words to guess.
Hope This Helps !
Felice, one good method of storing text data and removing the spaces between words is to make the first letter of the word 8th bit set and the rest not - until you get to the next word that is.
With sprite data solely, let's see ... calculating ... that would give you 8192-characters for words. If you chomp through SFX and music - you would get 17152-bytes for usage.
[Please log in to post a comment]