





Hi guys.
I'm not going to call this a bug cause it really isn't. However it is pretty inconvenient.
In light of the recent data compressor I wrote:
https://www.lexaloffle.com/bbs/?tid=50713
I am required to encode characters "0" (zero) to "9" as "\48" to "\57"
Why ? Well quite simply the system recognizes that \0 to \9 are read as single characters. So suppose you wanted to have character CHR(4) and character "8" in a string for data.
Well normally you would encode that as "\48" but now you see the problem. That also makes chr(48) which is character zero.
What I propose is, and you can make it optional, that "\" followed by a digit is disallowed as you can use \" for character 34 and all other non-printables like chr(10) and chr(13) already have equivalents.
This is controlled inside the code itself, possibly with an obscure POKE or even the command, nnbd() for "No numeric backslash definitions."
This of course also means that you would no longer have "\0" but a new character as
|
|
[8x8] |
Achieved and retrieved from printh(chr(0),"@clip")
In this with "\digits" no longer being viable, true 256-byte data can be stored with a minimal of fuss and not requiring coders to use \48 to \57 for simple digits 0 (zero) through 9.

You actually can write character 4 without it getting confused due to it being followed by a number; just prefix it with one or two zeros. "\004" works just fine. "\015" is great. Even "\000" is just one letter according to #.
However, if you have too many digits, it will lop some off of the escape sequence until it is three characters or less. The following image sums it up nicely:
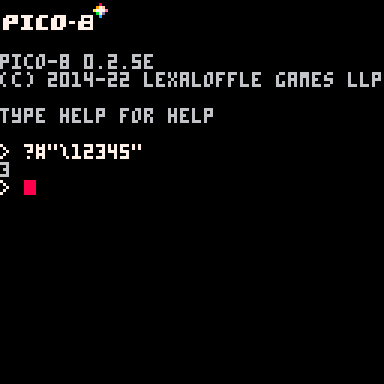
As you can see in the image, \123 are treated as one character, but the other characters - 4 and 5 - are not. (After all, what would character twelve-thousand-three-hundred-and-forty-five even be?)
Oh, and by the way, "\321" (or any number greater than 255 but less than 1000) will result in a syntax error.
Hi @Kaius. Thanks for your interest !
The whole process is to use minimal characters to define all 256-characters that can be read from a string written in source-code.
Now can't do anything about \0, yet all other characters are pretty well clear for one character except for special characters such as #10, #13, #34, #48-#57, and #92.
I am definitely trying to avoid 3-digits or 3-characters if at all possible, especially for digits.
As for the "\321" that is most interesting ! I did not know you could get an error from this.

I would not want this change because it would break existing carts that contain binary data encoded in strings.
Hi @dredds.
Thank you for your interest !
As I mentioned above Pico-8 would not change one bit.
It would require you to use the command, "nnbd()"
If you did not use the command, Pico-8 would function exactly as it does now.
Every suggestion I have ever made for Pico-8 would always be optional, requiring either an obscure poke, extra extcmd() command, or a special new command to enable.
So ... no. It would not break existing carts.

@dw817, I'm sure you know this ~
There is only one value that must be encoded as a numeral.
00 can be encoded as \0 unless followed by numeric digit character(s) 0-9 then must be fully encoded as \000, all other values have a single symbol or escape encoding. e.g.
09 > \t
10 > \n
13 > \r
34 > \"
93 > \\
Hi @aced. Thanks for your interest !
Actually character 9 I found can be chr(9) and does not require \t as long as it stays in Pico-8 and not Notepad or some other text editor.
You can test this by:
printh(chr(9),"@clip")
print ord("a")
|
Run the code. You will get 97.
Now return to source-code edit, Put the cursor on the second quote. Press backspace and CTRL+V. Then run again. You will get 9 as the result even though the actual character cannot be seen.
I was just wondering since chr(1) has its own unique image of "¹" that chr(0) zero could be encoded as "⁰"

@dw817,
I think the reason that zero doesn't have a glyph is that it's actually used as the control code for "stop printing text", so seems like zep didn't think it made sense to give it something to print out. I don't know if this could be changed, but aside from increasing the compressed size of data strings by a few bytes, it hasn't seemed to be a problem up to this point.
Hi @JadeLombax.
Most of the data I save to code is full of zeroes though. It would help to have ⁰ but it's not required.
I think the one that really bugs me is the necessity to have \48 to \57 for digits as there is no way to "bypass" interpreting \ digits as just the characters they are.
Current: \48\49 "12" length = 2
Changed: \48\49 "\" "4" "8" "\" "4" "9" length = 6
Where changed would be a unique way of interpreting a string definition coded in the source.
@dw817 - thanks for the tip on 09. You're quite right: Tab can be encoded ok.
I decided to use the escaped form \t as white-space characters are prone to getting mangled...
I agree, adding the ⁰ to P8SCII would seem appropriate- as we have a run of digits 1-8. It is a common value when encoding data.
Thanks for your support, @aced.
The ⁰ would save a byte. Lor' I think this whole thing was written - to save a byte.
Maybe some of it got lost in translation. :)
[Please log in to post a comment]