





Hey !
You may have already heard about virtual sprite from Poom devlog ( @freds72) and one high memory implementation from @pancelor. Here is my take.

{kind=link}
As a reminder, the principle of virtual sprite is to have a kind of "palette of sprite" which allow to draw more sprite than the 256 native built-in ones.
The cartridge contains 4 PX9 compressed spritesheet that are unpacked when the cartridge boot. Then a bunch of benchmark are launched to test the LRU Cache with differents configurations.
Implementation overview
I implement two types of LRU cache and a benchmark to challenge implementations. With LRU cache, the oldest sprite are replaced by the new ones when cache is full. Easier to say than to do ! To keep track of sprite age, I use an queue, implemented with LUA tables.
I use a 2 implementations of the lru age queue, one with the native del, deli, add function, and one with customs ldel, laddlast function relying on queue/linkedlist principle. My goal with linked list is to avoid shifting all table elements and reduce cpu cost of del/deli function. These two additionnal functions costs 134 tokens, maybe it can be improved...
I also implement one type of cache that handle 8x8 sprites, (256 in spritesheet and 1024 virtuals) and another with 16x16 sprites (64 in spritesheet and 256 virtual).
8x8 sprites exactly match what pico8 can do with spr function but it has to deal with heavier table to handle sprite age in cache. 16x16 sprites are... bigger which can be a pros or a cons, but in both case they reduce the size of the cache and should reduce overhead to handle them. It is the choice that @freds72 has made in poom.
Finally, I added a FIFO policy to the cache, which has the advantage of being simple and needs low cpu. We can see if this is an interesting approach.
Results
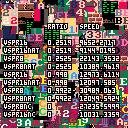
To comment the results, I would say that 16x16 sprites are handled better, because even if pico8 draw less sprites per sec, each sprite is 4 times bigger. That said you can multiply the number of sprite per second and you will have more 8x8 sprites.
We can also see that with 16x16 sprites, the overhead of native del function is not to much of a problem.
With 8x8 sprites, you have a huge gain with linked list queue, because we never shift the whole 1023 elements in the age queue. So if can you afford the 134 tokens and have to deal with 8x8 sprites, this choice is interesting.
The worst choice to make is to deal with 8x8 sprites and native del function to handle lru cache. I think in this case the overhead simply discard the benefits of the cache.
EDIT: With the vspr function provided by @JadeLombax, we can see that LRU implementation overhead never provide better results. Even with high cache hit ratio, it barely reach the performance with cache. It means that sprite copy is already fast, so if we want to handle a kind of cache to avoid double copy for each sprite drawing, we need a low overhead cache mechanic. So I try a FIFO cache.
If you want to test your own functions
On tab 2, there is a table for benchmark declaration. The table benchs contain entries where :
nis the name of benchmark,fthe function to call to draw a sprite from high memory. The Function as 3 parameters, fun(sprite_nb,x,y). Sprite number is the absolute number of sprite among the 4 highmemory bank, with 8x8 sprite, it can be 0-1023.dis the data preset. I use 4 presets, randomly populated 32767 sprite index at boot time.
ben8andben8fare for 8x8 sprite. ben8 can have sprite with index 0 to 1023, which imply a ~25% hit ratio as it is pure random.ben8fonly have 0 to 255 sprite index, which implies 100% hit ratio.
ben16andben16fare the same for 16x16 sprite.ben16has ~25% hit ratio andben16f~100%
local benchs={
{n="jadelombax",f=vspr,d=ben8},
{n="vspr8memcpy",f=vspr8nc,d=ben8},
{n="vspr8lru ",f=vspr8,d=ben8},
{n="vspr8fifo",f=vspr8fifo,d=ben8},
{n="vspr8lru ",f=vspr8,d=ben8f},
{n="vspr8fifo",f=vspr8fifo,d=ben8f},
{n="vspr16lru",f=vspr16,d=ben16},
{n="vspr16fifo",f=vspr16fifo,d=ben16},
{n="vspr16lru",f=vspr16,d=ben16f},
{n="vspr16fifo",f=vspr16fifo,d=ben16f},
{n="vspr16nc ",f=vspr16nc,d=ben16},
} |
So you can add your function and declare it in the benchs, it should work :)


Interesting, I just made a little virtual sprite function myself. I'm wondering, though, how would one compare the speed of a function that doesn't use a cache?
@JadeLombax
You're right to measure the cache gain it could be interesting to see how vspr works without any cache. We can reduce cache size to 1, but there will be some overhead. So I add two function, vpsr8nc and vpsr16nc without any cache to catch that information. Sprite is always copied to sprite 0, then spr draw it to screen
Results are interesting, with a high hit ratio, we have better performance with cache than without. But with a lower hit ratio, at some point no cache is faster ! I may have to improve my code to see if I can reduce overhead.
Another point is that in the benchmark I use the full sprite sheet. With a smaller cache size, we could also reduce overhead.
Cool, thanks for doing that.
I plugged in my function and it actually seems to be a bit faster than both cached versions, though because of this it's running into Pico-8's number limits. Here's the function, it's limited to just 8x8 sprites so far, but it's just 41 tokens:
function vspr(n,x,y) local ssp=32768+n\16*512+n%16*4 for i=0,448,64 do poke4(i,$(ssp+i)) end spr(0,x,y) end |
Oh well done ! I use memcpy without thinking to much how it costs, but it seems to use a lot more cpu than poke4 !
poke4 is a perfect match for copying sprites
I’ll try to bench Poom vspr against your framework.
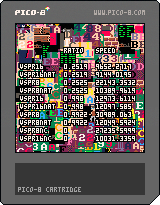
Just add efficient @JadeLombax vspr, with short poke4.
I also add a time column to avoid 16bit limitation encounter with number of sprite / sec
I also use poke4 in 16x16 sprites and kept a memcpy with no cache to compare with @JadeLombax vspr
With this new results, we can see that the overhead of keeping age the way I implemented doesn't worth it. I'll try simpler cache implementation to see if it is possible to have some more gain
[Please log in to post a comment]