






Answer: Quite a few! But you probably have better options.
I've previously seen PICO-8 decoders for hex and base-64 strings. Recently I was curious: which base is most efficient? There are a lot more possibilities than just 16 or 64, and I knew PICO-8's code compression would affect the actual efficiency.
So I ran an experiment.
The experiment: I wrote a script to generate a bunch of .p8 files containing random data, and I exported them all through PICO-8 v0.2.2c to see how long the random data could get before PICO-8 would complain. The random data was in the form of strings in a given base: e.g., for base 16, the cart's entire program was x="(random hex string)". I generated these carts from base 2 (just "0" and "1") up to base 92 (almost every printable ASCII character). I ran several trials for each base because using random strings causes some variation in the measurements. I then counted the theoretical information content of each string (e.g., log-base-2 of the alphabet size) and converted the average for each base to kilobytes.
My initial hypothesis: There would be a few different sweet spots where the size of the alphabet would play better with PICO-8's code compression. Specifically, I had my metaphorical money on base 48 because the indexes 0-47 work well with PICO-8's move-to-front encoding.
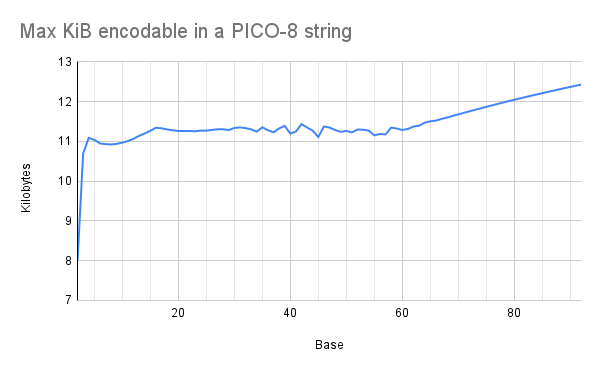
The actual result: There are no clear sweet spots! Small bases are less efficient, but efficiency plateaus around base 16. And if you go much higher than base 64, you get a gradual linear increase in efficiency.
So what's going on here?
It turns out that PICO-8 does a surprisingly good job of compressing strings. Even with a random hex string, you still get quite a few 4-digit substrings that occur multiple times in the data, just by chance (something something birthday paradox). PICO-8 can encode these repetitions efficiently (yay compression!), so even though a hex digit carries fewer bits of information than a base-64 digit, PICO-8 can store proportionally more of them.
(Note that this doesn't break any laws of data compression! PICO-8 is compressing random hex digits to around 5.38 bits/digit, whereas the theoretical minimum is 4 bits. PICO-8 isn't beating the universe. It's just beating its own move-to-front encoding, which can do hex digits at 6 bits/digit.)
The plateau happens because as the base increases, the data gets harder to compress. Each digits carries more bits, but the string cannot be as long because PICO-8 can't compress it as well, and the two factors cancel out each other.
The linear section after base 64 happens, I suspect, because when PICO-8 can't compress a section of the data, it falls back to encoding raw bytes for that section. So at that point, the base of the string doesn't matter -- it always costs 8 bits to encode each digit, no matter what the base is. I haven't tested it, but I suspect base-128 would work well if you had to stuff a whole lot of data into a string.
All that said, a lot of this isn't very pragmatic for actually making carts. There are better places to store binary data (e.g., the map section of the cart) and there are better ways to encode specific types of data (e.g., PX9 for images). But I had fun doing running this experiment, and I haven't seen any other discussions like this, so I figured I'd share the results in case anyone else was pondering similar things.
 9 comments
9 comments
In PICO-8, the % operator causes numbers to wrap like this:
print(-1 % 10) -- 9 print(0 % 10) -- 0 print(1 % 10) -- 1 |
As I understand it, to compute x % y, you take x and add/subtract y from it, making it bigger if it's negative and smaller if it's too big, until x >= 0 and x < y. As long as y is not zero, the result should always be positive.
Well, -32768 % y is negative for some values of y:
print(-32768 % 20000) -- negative result: -12768 |
After trying a bunch of values for y, the rules look... complicated:
- If -0x4000 <= y and y <= 0x4000, then x % y is positive 32768 minus abs(y) a bunch of times, until it's in the proper range.
- If y < -0x4000 or 0x4000 > y, then x % y is -32768 plus abs(y) multiple times, but not enough times to make the number non-negative.
Is this a bug? This doesn't seem like intended (or useful) behavior to me.